Część 2
Wszystkie nowoczesne standardy zapisu informacji używają jednego języka zapisu, XML. Jest to język uniwersalny, prosty i łatwy do opanowania, a jednoczesnie ma ogromną moc ekspresji. Adres Instytutu możemy w XML zapisac płasko:
<adres>180 Second Avenue, New York, NY</adres>
albo hierarchicznie:
<galaktyka nazwa=”Droga Mleczna„>
<gwiazda nazwa=”Sol„>
<planeta nazwa=”Mars„/>
<planeta nazwa=”Ziemia„>
<kontynent nazwa=”Ameryka Północna„>
<panstwo nazwa=”USA„>
<stan nazwa=”Nowy Jork„> […] itp.
</stan>
</panstwo>
</kontynent>
</planeta>
</gwiazda>
</galaktyka>
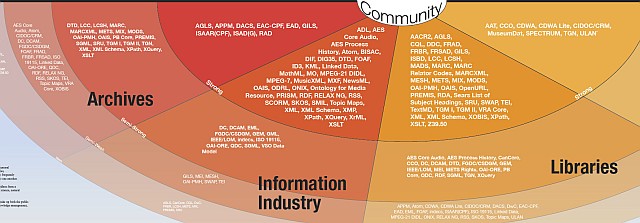
EAD jest standardem (wyrażanym w XML) opracowanym dla archiwów i jest bardzo typowym przykładem opisu hierarchicznego. Jest odbiciem typowej organizacji archiwum, gdzie kolekcja (zespół archiwalny, fonds) może byc podzielona na pod-zespoły (subfonds), te z kolei na serie, podserie, grupy, podgrupy itp. Często organizacja taka nie jest sprawą wyboru, gdy na przykłład oryginalny twórca danej kolekcji tak ją właśnie uporządkował. Zasada szacunku dla oryginalnego twórcy kolekcji (respect de fonds) wymaga pozostawienia w miarę możności oryginalnej organizacji.
Czytaj dalej „Standardy metadanych dla archiwów: płaskie czy hierarchiczne? (Cz. 2)”

 EAD (Encoded Archival Description) jest standardem stworzonym specjalnie w celu zakodowania pomocy archiwalnych. Z tego powodu jest on pewnego rodzaju hybrydą. Z jednej strony stara się odzwierciedlić sposób, w jaki pracują archiwiści tworząc pomoce archiwalne, z drugiej stara się wprowadzić dyscyplinę i dokładność niezbędną do elektronicznej obróbki dokumentu. W wyniku mamy sporo dowolności w umiejscowieniu danych, co ułatwia pracę archiwiście a jednocześnie utrudnia wymianę danych. W nowej wersji EAD (EAD3), która jest w przygotowaniu od kilku lat, spodziewane jest zmniejszenie tych dowolności.
EAD (Encoded Archival Description) jest standardem stworzonym specjalnie w celu zakodowania pomocy archiwalnych. Z tego powodu jest on pewnego rodzaju hybrydą. Z jednej strony stara się odzwierciedlić sposób, w jaki pracują archiwiści tworząc pomoce archiwalne, z drugiej stara się wprowadzić dyscyplinę i dokładność niezbędną do elektronicznej obróbki dokumentu. W wyniku mamy sporo dowolności w umiejscowieniu danych, co ułatwia pracę archiwiście a jednocześnie utrudnia wymianę danych. W nowej wersji EAD (EAD3), która jest w przygotowaniu od kilku lat, spodziewane jest zmniejszenie tych dowolności.