Zegar astronomiczny w Pradze By Steve Collis from Melbourne, Australia (Astronomical Clock Uploaded by russavia) [CC BY 2.0], via Wikimedia Commons
W jednym z poprzednich wpisów na blogu “Czy umiemy pisać daty?” omawiałem podstawy uniwersalnej notacji czasu i dat, zdefiniowanej w międzynarodowym standardzie ISO 8601 i jego uproszczonej wersji konsorcjum W3C. Od tego czasu Biblioteka Kongresu Amerykańskiego zakończyła prace nad rozszerzonym standardem, Extended Date/Time Format (EDTF) 1.0. Większa część EDTF dotyczy zapisu nieprecyzyjnych dat. Taka niedokładna lub nieprecyzyjna informacja dotycząca czasu występuje często w zapisach wydarzeń historycznych, np. w archiwach czy naukach bibliotecznych. Standard ISO 8601 nie pozwala na wyrażenie takich konceptów jak “w przybliżeniu rok 1962”, “któryś rok pomiędzy 1920 a 1935” czy “wydarzenie miało prawdopodobnie miejsce w roku 1938, ale nie jesteśmy tego pewni”. Standard EDTF pozwala na zapisanie w postaci zrozumiałej przez komputer takich konceptów, wypełniając potrzeby istniejące w wielu polach wiedzy mających do czynienia z metadanymi o charakterze historycznym.
Mimo tego, że standard EDTF jest stosunkowo nowy i nie ma zbyt wiele narzędzi programowych pomagających wprowadzać takie dane, sądzę, że warto jest zaznajomić się z tą nowa notacją i używać jej w miarę możliwości
I wszystko, co się z tym wiąże: segregowanie, redukowanie, pakowanie, przewożenie, rozpakowywanie, ustawianie….? O ile można w miarę sprawnie przenieść się z mieszkania do mieszkania, to przeprowadzenie zmiany lokalu instytucji, która od ćwierćwiecza zajmowała kamienicę w centrum Manhattanu, gromadząc archiwa, dzieła sztuki i eksponaty muzealne, trudno sobie wyobrazić.
Wieść o sprzedaży domu, który wynajmował Instytut Piłsudskiego w Ameryce na swoją siedzibę, była dużym zaskoczeniem dla jego pracowników. Instytut kojarzony był od wielu lat z Drugą Aleją na Manhattanie, miał stałe grono przyjaciół, wielbicieli, odwiedzających oraz badaczy, a tu nagle taka wiadomość! Niełatwo było się z nią pogodzić, ale innego wyjścia nie było. Niezwłocznie zorganizowano Kampanię Na Rzecz Przyszłości w celu zebrania funduszy na to przedsięwzięcie i opracowano logistykę zmiany lokalizacji. Przygotowania trwały ponad rok. Przede wszystkim musieliśmy znaleźć nową siedzibę, która pomieściłby nasze zbiory i zapewniła sprawne kontynuowanie działalności Instytutu. Najbardziej przypadł nam do gustu lokal zaproponowany przez Polsko-Słowiańską Federalną Unię Kredytową, a także warunki jego wynajmu. Rozpoczęły się prace adaptacyjne: zaprojektowanie i zabudowanie wnętrza, instalacja profesjonalnych zabezpieczeń, regałów oraz montowanie przestronnych szaf. Nieocenioną pomoc otrzymaliśmy z Instytutu Pamięci Narodowej, z którego oddelegowano ośmiu archiwistów, którzy w ciągu dwóch miesięcy profesjonalnie i sprawnie zapakowali archiwa oraz zbiory biblioteczne i pomagali w przenoszeniu ich do nowego lokum. Nie byliśmy w stanie policzyć tych wszystkich pudeł i paczek, które po przewiezieniu na nowe miejsce, zajęły większość powierzchni użytkowej, piętrząc się niemal pod sufit.
Jednym z najważniejszych zadań systemu zarządzania aktami (RM) jest dokumentowanie działalności instytucji czy organizacji, tworzenie zapisanej i niezmienialnej pamięci jej działalności i historii, zapisywanie dowodów które mogą być użyte (np. przez historyka lub sąd) z pewnością, że nie zostały one zmienione czy zafałszowane. W tym aspekcie MoReq2012 jest istotny również dla archiwów, których funkcja pokrywa się w dużym stopniu z tymi zadaniami.
Moduły MoReq2010
MoReq2010 – wymagania sytemu zarządzania aktami – jest podzielone na moduły, które opisują różne działy albo funkcje oprogramowania. Moduły to jednocześnie serwisy, części oprogramowania które te funkcje spełniają. Niektóre rodzaje serwisów są już w powszechnym użyciu w prawie każdym systemie wielo-użytkownikowym, niektóre są specyficzne dla MoReq.
Moduły obsługujące użytkowników to Grupy Użytkowników i modelowy Moduł Ról. Zadaniem modułu użytkowników jest zarządzanie użytkownikami i ich grupami, podobnie do istniejących użytkowników w systemach komputerowych, ale z konkretnymi ograniczeniami (np. nie wolno ponownie używać identyfikatorów itp.). Moduł ról opisuje role jakie moga przyjmować użytkownicy, i możliwości dostępu do przypisane tym rolom. Jan Kowalski może więc na przykład należeć do grupy Działu Handlowego, i posiadać rolę Administratora z prawami dodawania nowych użytkowników, ale tylko w tym dziale.
MoReq2010 jest najnowszym europejskim standardem opisującym wymagania systemu zarządzania aktami (RM = record management).
Dlaczego powinniśmy się w ogole interesować RM? Zarządzanie aktami dotyczy przede wszystkim instytucji czy firm które takie akta wytwarzają. Pozornie dobry system szafek na dokumenty, segregatorów, ksiąg korespondencji przychodzącej i wychodzącej powinien być całkowicie wystarczający. Stare biurokracje o tradycji sięgającej Bizancjum (a do takich należy w dużym stopniu Polska) posiadają takie zwyczaje w nadmiarze. Ale system o tak starej tradycji jest trudny do zmodyfikowania, a czas dokumentów elektronicznych, łatwości kopiowania informacji, rozproszenia geograficznego firm itp. tworzy wyzwania którym trudno jest już dziś sprostać. Archiwa, jak każe tradycja, wcześniej lub później dostaną takie kolekcje dokumentów generowanych masowo wewnątrz ministerstw, ambasad, firm i instytucji użyteczności publicznej, i powinny być żywotnie zainteresowane, w jakim stanie i w jakiej formie te dokumenty będą przekazane.
Zarządzanie dokumentami (RM) zajmuje się konceptualnie prostymi problemami. Dla ułatwienia można sobie wyobrazić zapis narady prezydenckiej w Białym Domu albo zapis wizyty i badania u lekarza. Dokument trzeba przechować i opublikować, aby był dostępny dla jego użytkowników. Trzeba go zaklasyfikować do właściwej kategorii (szuflady, teczki, przegródki). Trzeba określić, kto w ogóle może go czytać, a kto (i kiedy) może go zmodyfikować. Czy można robić kopie, a jeśli tak, to gdzie będą przechowywane. Trzeba zapisać historię tego dokumentu. Trzeba określić, jaki jest jego czas życia, i jaki będzie jego los po tego czasu upłynięciu: dokument może być np. usunięty, poszatkowany albo przekazany archiwum.
Wizualizacja spuścizny kulturowej: otwarte Linked Data w Carnegie Hall cz. 2
Przedstawiamy drugą część gościnnego blogu Roberta Hudsona, archiwisty z Carnegie Hall w Nowym Jorku. W drugim odcinku Rob opowiada o wynikach swojej pracy nad przekształceniem bazy danych Carnegie Hall w postac otwartego Linked Data. Po dokonaniu konwersji i uzyskaniu ok miliona „trójek” RDF, pora na dotarcie do narzędzi pozwalających na wizualizację i przeglądanie danych. Blog jest ilustorowany nagraniami pokazującymi na żywo eksploracje danych, z komentarzem autora.
Part II: Product
In Part I of this blog, I began telling you about my experience transforming Carnegie Hall’s historical performance history data into Linked Open Data, and in addition to giving some background on my project and the data I’m working with, I talked about process: modeling the data; how I went about choosing (and ultimately deciding to mint my own) URIs; finding vocabularies, or predicates, to describe the relationships in the data; and I gave some examples of the links I created to external datasets.
In this installment, I’d like to talk about product: the solutions I examined for serving up my newly-created RDF data, and some useful new tools that help bring the exploration of the web of linked data down out of the realm of developers and into the hands of ordinary users. I think it’s noteworthy that none of the tools I’m going to tell you about existed when I embarked upon my project a little more than two years ago!
As I’ve mentioned, my project is still a prototype, intended to be a proof-of-concept that I could use to convince Carnegie Hall that it would be worth the time to develop and publish its performance history data as Linked Open Data (LOD) — at this point, it exists only on my laptop. I needed to find some way to manage and serve up my RDF files, enough to provide some demonstrations of the possibilities that having our data expressed this way could afford the institution. I began to realize that without access to my own server this would be difficult. Luckily for me, 2014 saw the first full release of a linked data platform called Apache Marmotta by the Apache Software Foundation. Marmotta is a fully-functioning read-write linked data server, which would allow me to import all of my RDF triples, with a SPARQL module for querying the data. Best of all, for me, was the fact that Marmotta could function as a local, stand-alone installation on my laptop — no web server needed; I could act as my own, non-public web server. Marmotta is out-of-the-box, ready-to-go, and easy to install — I had it up and running in a few hours.
In addition to giving me the capability to serve up, query, and edit my RDF data, Marmotta has some great built-in visualization features. The screencast below demonstrates one of the map functions, with which I can make use of the GeoNames URIs I’ve used in my dataset to identify the birthplaces of composers and performers.
Wizualizacja spuścizny kulturowej: otwarte Linked Data w Carnegie Hall cz. 1
Rob Hudson – Photo by Gino Francesconi
Przedstawiamy gościnny blog Roberta Hudsona, archiwisty z Carnegie Hall w Nowym Jorku. Rob jest z wykształcenia muzykiem, zainteresowany archiwami, pracuje w Carnegie Hall od 1977 roku. Odkrywszy bazę danych występów w Carnegie Hall sięgających 19 wieku, Rob postanowił nauczyc sie programowania i dokonać konwersji danych w postać otwartego Linked Data tak, aby można było odkrywać powiązania i informacje o kompozytorach, wykonawcach i koncertach. Wielu polskich twórców i wykonawców przez lata brało udział w przedstawieniach w Carnegie Hall. Inicjatywa Roba przyczyni się, miejmy nadzieję, do udostępnienia ciekawego rozdziału z historii muzyki również polskim fanom.
Part I: Process
My name is Rob Hudson, and I’m the Associate Archivist at Carnegie Hall, where I’ve had the privilege to work since 1997. I’d like to tell you about my experience transforming Carnegie Hall’s historical performance history data into Linked Open Data, and how within the space of about two years I went from someone with a budding interest in linked data, but no clue how to actually create it, to having an actual working prototype.
First, one thing you should know about me: I’m not a developer or computer scientist. (For any developers and/or computer scientists out there reading this right now: skip to the next paragraph, and try to humor me.) I’m a musician who stumbled into the world of archives by chance, armed with subject knowledge and a love of history. I later went back and got my degree in library science, which was an incredibly valuable experience, and which introduced me to the concept of Linked Open Data (LOD), but up until relatively recently, the only lines of programming code I’d ever written was a “Hello, World!” – type script in Basic — in 1983. I mention this in order to give some hope to others out there like me, who discovered LOD, thought “Wow, this is fantastic — how can I do this?”, and were told “learn Python.” Well, I did, and if I can do it, so can you — it’s not that hard. Much harder than learning Python — and, one might argue, more important — is the much more abstract process of understanding your data, and figuring out how to describe it. Once you’ve dealt with that, the transformation via Python is just process — perhaps not a cakewalk, but nonetheless a methodical, straightforward process that you can learn and tackle, step by step.
Wszystkie nowoczesne standardy zapisu informacji używają jednego języka zapisu, XML. Jest to język uniwersalny, prosty i łatwy do opanowania, a jednoczesnie ma ogromną moc ekspresji. Adres Instytutu możemy w XML zapisac płasko:
EAD jest standardem (wyrażanym w XML) opracowanym dla archiwów i jest bardzo typowym przykładem opisu hierarchicznego. Jest odbiciem typowej organizacji archiwum, gdzie kolekcja (zespół archiwalny, fonds) może byc podzielona na pod-zespoły (subfonds), te z kolei na serie, podserie, grupy, podgrupy itp. Często organizacja taka nie jest sprawą wyboru, gdy na przykłład oryginalny twórca danej kolekcji tak ją właśnie uporządkował. Zasada szacunku dla oryginalnego twórcy kolekcji (respect de fonds) wymaga pozostawienia w miarę możności oryginalnej organizacji.
Na niedawnej konferencji METRO (Metropolitan New York Library Council) miała miejsce prezentacja przedstawicieli grupy ‘Humanistyka Cyfrowa w New York City’ (NYCDH). Grupa ta działa od połowy 2011, i zrzesza zainteresowanych Humanistyką Cyfrową z Nowego Jorku i okolic. Dostarcza ona forum wielu różnym organizacjom i małym grupom osób które pracują nad jakimiś problemami związanymi z humanistyką cyfrową. Uczelnie, w których pracują członkowie komisji sterującej grupy (takie jak NYU, CUNY, Columbia, Pratt i inne) udzielają miejsca na spotkania. Kalendarz grupy jest pełny, często jest kilka wydarzeń lub spotkań w tygodniu. Grupa jest otwarta, i po zarejestrowaniu się każdy członek może wpisać w kalendarz imprezę jaka organizuje i wziąć udział w już ogłoszonej.
Na stronie NYCDH można znaleźć grupy dyskusyjne o wielu tematach takich jak “Pedagogika Cyfrowa”, “Grupa OMEKA”, “Bibliotekarze w Humanistyce Cyfrowej”, “Grupa analizy tekstu”, “Grupa eksperymentów cyfrowych”, “Antyki i techniki cyfrowe” i inne. Planowane na najbliższy okres i niedawno zakończone imprezy dobrze obrazują działalność grupy.
Własność intelektualna w naukach humanistycznych – panel dyskusyjny z udziałem administratora uczelni, prawnika, bibliotekarza i studenta o napięciach pomiędzy egzekwowaniem praw a uczelnianą tradycją otwartego zdobywania wiedzy.
Muzeum po-cyfrowe – wykład Ross Perry z University of Leicester.
Przy planowaniu procedur i etapów pracy projektu digitalizacji zasobów archiwalnych Instytutu zastanawialiśmy się nad tym, jakiego standardu użyć przy opisie digitalizowanych dokumentów. Po wykonaniu skanu czyli zapisu obrazu dokumentu, niezbędnym jest jego opisanie tak, aby możliwe było znalezienie interesującej czytelnika informacji. Idealnie byłoby dokonać transkrypcji całości materiału, ale przy dużej ilości ręcznie pisanych dokumentów były to tylko marzenia. Proces znajdywania i organizowania informacji o tekście, zdjęciu itp. czyli tak zwanych metadanych (danych o danych) oraz zapisywania ich w odpowiedniej bazie danych jest najważniejszyma (i najbardziej czasochłonnym) etapem digitalzacji.
Jest wiele schematów i standardów zapisu i transportu metadanych, więcej niż można łatwo ogarnąć ciekawie brzmiących skrótów: DC, EAD, MARC, MODS, TEI, AACR2, CCO, CDWA, DACS, FOAF, ISAD(G), METS, OAI-PMH, OAIS, OWL, POWDER, PREMIS, RDA, RDF, SWORD itp. Nawet ograniczając się do standartów opisu metadanych zawartości dokumentów, mieliśmy do wyboru DC, EAD, MARC i TEI. Przy testach pojawił się problem hierarchizacji informacji, który w zasadzie ciągle jest z nami, mimo prób jego oswojenia.
Ilustracja wykonana z użyciem „Wikipedia logo bronce” by User:Nohat [CC-BY-SA-3.0], via Wikimedia Commons”
Archiwa to repozytoria dziedzictwa kulturowego człowieka które, zachowując oryginalne dokumenty i artefakty z przeszłości, odzwierciedlają wspólną historię. Ich zadaniem jest chronić te zasoby i udostępniać je wszystkim. Misją Wikipedii jest jest dostarczyć podstawową wiedzę, udostępniając ją swobodnie i bez ograniczeń. Archiwa są więc naturalnym kandydatem do współpracy z Wikipedią, do wykorzystania zasobów i możliwości obu z nich. Artykuł ten jest częściowo oparty na doświadczeniach układu partnerskiego Instytutu Piłsudskiego z Wikipedią w ciągu ostatniego półtora roku.
Dlaczego Wikipedia?
Wikipedia jest największą encyklopedią, dostępną dla wszystkich. Każdy, kto ma dostęp do Internetu może korzystać z niej korzystać. Wikpedia ma około pół miliarda odsłon miesięcznie, 250 wersji językowych i zawiera około 20 milionów artykułów. (Polska wersja ma ponad milion artykułów i jest w pierwszej dziesiątce na świecie). Użytkownicy coraz częściej sięgają po Wikipedię dla uzyskania podstawowych informacji na każdy temat, zwłaszcza dotyczy to młodszego pokolenia, dla którego komputer i internet to narzędzia codziennego użytku.







 Jednym z najważniejszych zadań systemu zarządzania aktami (RM) jest dokumentowanie działalności instytucji czy organizacji, tworzenie zapisanej i niezmienialnej pamięci jej działalności i historii, zapisywanie dowodów które mogą być użyte (np. przez historyka lub sąd) z pewnością, że nie zostały one zmienione czy zafałszowane. W tym aspekcie MoReq2012 jest istotny również dla archiwów, których funkcja pokrywa się w dużym stopniu z tymi zadaniami.
Jednym z najważniejszych zadań systemu zarządzania aktami (RM) jest dokumentowanie działalności instytucji czy organizacji, tworzenie zapisanej i niezmienialnej pamięci jej działalności i historii, zapisywanie dowodów które mogą być użyte (np. przez historyka lub sąd) z pewnością, że nie zostały one zmienione czy zafałszowane. W tym aspekcie MoReq2012 jest istotny również dla archiwów, których funkcja pokrywa się w dużym stopniu z tymi zadaniami.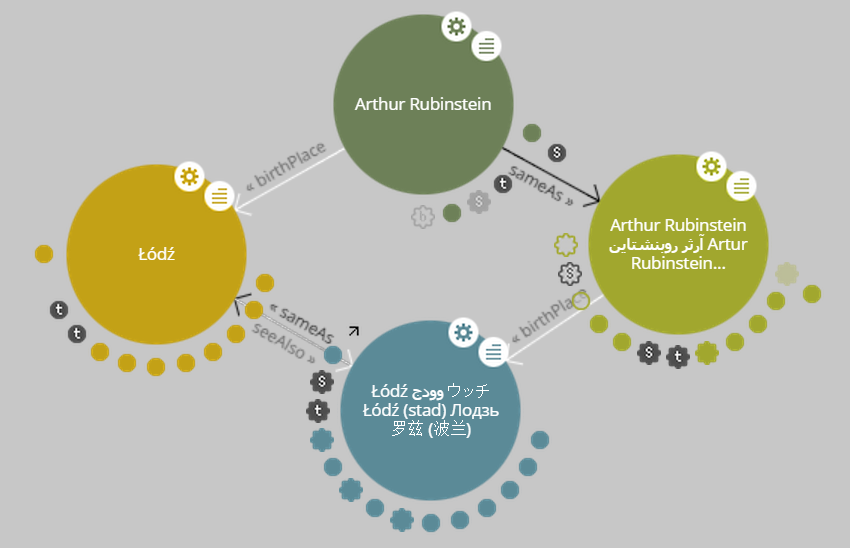




 Na niedawnej konferencji METRO (Metropolitan New York Library Council) miała miejsce prezentacja przedstawicieli grupy ‘Humanistyka Cyfrowa w New York City’ (NYCDH). Grupa ta działa od połowy 2011, i zrzesza zainteresowanych Humanistyką Cyfrową z Nowego Jorku i okolic. Dostarcza ona forum wielu różnym organizacjom i małym grupom osób które pracują nad jakimiś problemami związanymi z humanistyką cyfrową. Uczelnie, w których pracują członkowie komisji sterującej grupy (takie jak NYU, CUNY, Columbia, Pratt i inne) udzielają miejsca na spotkania. Kalendarz grupy jest pełny, często jest kilka wydarzeń lub spotkań w tygodniu. Grupa jest otwarta, i po zarejestrowaniu się każdy członek może wpisać w kalendarz imprezę jaka organizuje i wziąć udział w już ogłoszonej.
Na niedawnej konferencji METRO (Metropolitan New York Library Council) miała miejsce prezentacja przedstawicieli grupy ‘Humanistyka Cyfrowa w New York City’ (NYCDH). Grupa ta działa od połowy 2011, i zrzesza zainteresowanych Humanistyką Cyfrową z Nowego Jorku i okolic. Dostarcza ona forum wielu różnym organizacjom i małym grupom osób które pracują nad jakimiś problemami związanymi z humanistyką cyfrową. Uczelnie, w których pracują członkowie komisji sterującej grupy (takie jak NYU, CUNY, Columbia, Pratt i inne) udzielają miejsca na spotkania. Kalendarz grupy jest pełny, często jest kilka wydarzeń lub spotkań w tygodniu. Grupa jest otwarta, i po zarejestrowaniu się każdy członek może wpisać w kalendarz imprezę jaka organizuje i wziąć udział w już ogłoszonej.

.jpg){kind=link}