
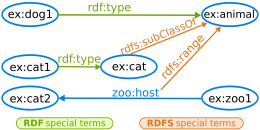
|
Przykład schematu RDF Linked Data (reifikacja) – autor Karima Rafes (własne dzieło) [CC-BY-SA-3.0], via Wikimedia Commons) |

Linked Data to mechanizm którym posługuje się Semantic Web albo “Web 3.0 w budowie”. Te powiązane ze sobą określenia są tak nowe, że nie maja jeszcze ‘oficjalnego’ polskiego tłumaczenia. Na czym polega Semantic Web? Wszyscy używamy World Wide Web (www). Podstawowym składnikiem www sa tak zwane hiperłącza (hiperlink), odnośniki albo odsyłacze do innych stron, źródeł informacji. Kliknięcie w taki odsyłacz (ma w nazwie http) powoduje otwarcie w przeglądarce internetowej nowej strony pozwalającej na rozszerzenie naszej wiedzy lub dalsze zaspokojenie ciekawości. Www została stworzona dla naszej konsumpcji, i jak język naturalny, jest rozumiana przez ludzi.
Jak pisałem poprzednio, komputery są w porównaniu z nami bardzo mało rozgarnięte. Trzeba im wszystko przedstawiać kawa na ławę, metodą łopatologiczną. Ale są za to bardzo szybkie, a przede wszystkim potrafią ogarnąć o wiele więcej danych na raz niż my. A to znaczy, że odszukają w petabajtach informacji to, czego właśnie potrzebujemy. Aby to było możliwe, musimy być dużo bardziej precyzyjni, mieć wiarygodne źródła informacji i system który to wszystko połączy. Tym systemem jest właśnie Linked Data.



 W coraz większym tempie przestawiamy się na fotografię cyfrową. To, co było kilkanaście lat temu nowinką staje się standardem, a aparaty na film staja się rzadkością. Możliwość natychmiastowego sprawdzenia wyniku, powszechność zapisu obrazu w telefonach, tabletach, coraz tańsza pamięć cyfrowa i sprzęt fotograficzny powoduje, że robimy teraz o wiele więcej zdjęć. Jednocześnie jednak fotografia stała się czymś bardzo przejściowym. Kiedyś wklejało się zdjęcia do albumów, kolekcjonowało w pudełkach, dziś siedzą one jako pliki na dysku komputera, a gdy dysk padnie (wszystkie dyski to czeka), nagle tracimy nasze zasoby. Pisałem już wcześniej o
W coraz większym tempie przestawiamy się na fotografię cyfrową. To, co było kilkanaście lat temu nowinką staje się standardem, a aparaty na film staja się rzadkością. Możliwość natychmiastowego sprawdzenia wyniku, powszechność zapisu obrazu w telefonach, tabletach, coraz tańsza pamięć cyfrowa i sprzęt fotograficzny powoduje, że robimy teraz o wiele więcej zdjęć. Jednocześnie jednak fotografia stała się czymś bardzo przejściowym. Kiedyś wklejało się zdjęcia do albumów, kolekcjonowało w pudełkach, dziś siedzą one jako pliki na dysku komputera, a gdy dysk padnie (wszystkie dyski to czeka), nagle tracimy nasze zasoby. Pisałem już wcześniej o 
{kind=link}