
Crowdsourcing jest relatywnie nowym pomysłem, polegającym na powierzeniu jakiegoś zadania, tradycyjnie wykonywanego przez pracowników organizacji, grupie osób czy społeczności (crowd = tłum) poza tą organizacją. Różnica w stosunku do techniki outsourcing polega na tym, że zadanie powierzone jest nieznanej grupie jako publiczny apel, a nie jakiemuś konkretnemu ciału. Crowdsourcing, dzięki technologii Web. 2.0, uważany jest za narzędzie z dużymi perspektywami tak w przypadku komercyjnych organizacji jak i non-profit, jakimi są biblioteki i archiwa. Najbardziej znanym przykładem wykorzystania techniki crowdsourcing jest Wikipedia, czyli cyfrowa, powszechnie dostępna encyklopedia, tworzona przez internetowych wolontariuszy. Projekt ten w bardzo krótkim czasie i przy minimalnym koszcie doprowadził do powstania blisko 4 milionów artykułów w przypadku anlogjęzycznej wersji!
Autor: Marek Zieliński
Jak digitalizować mapy nie wydając fortuny
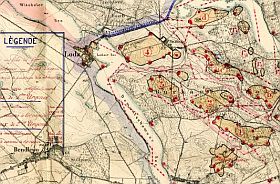

Fragment mapy z kolekcji Instytutu Piłsudskiego: Rozmieszczenie wojsk w okolicy Stęszewa z raportu Francuskiej Misji Wojskowej w Polsce, 1920 r.
Skanowanie dużych obiektów stanowiło zawsze wyzwanie dla archiwistów. Mapy, plakaty, i inne materiały o dużych formatach nie mieszczą się na stołach typowych skanerów o formacie A-3. Jednocześnie cena skanera rośnie eksponencjalnie ze wzrostem wielkości powierzchni skanowanej i często kupno skanera wielkoformatowego przekracza możliwości budżetowe instytucji. Jedną z opcji którą można zastosować zamiast skanera jest fotografia cyfrowa. Wymaga ona spełnienia wielu warunków, jak równomiernego oświetlenia, odpowiedniego systemu montowania kamery, płaskiego utrzymywania obiektu, korekcji na aberracje sferyczną i chromatyczną obiektywu itp. Największym ograniczeniem jest jednak ciągle nie wystarczająca rozdzielczość czujnika aparatów cyfrowych.
Jeszcze kilka lat temu braliśmy pod uwagę wynajęcie firmy profesjonalnej lub wysłanie archiwalnych map do archiwum posiadającego skaner wielkoformatowy. Jednakże postępy w oprogramowaniu do tworzenia panoram pozwoliło nam na opracowanie techniki, która kosztuje niewiele a pozwala na udostępnienie archiwalnych map w ich całej wspaniałości. Daje ona z możliwość podziwiania kunsztu grafików wojskowych i oglądania najmniejszych detali mapy. Technika ta polega na skanowaniu mapy w sekcjach a następnie sklejania ich, ale nie ręcznie a automatycznie, z użyciem odpowiedniego programu.
Co jest na odwrocie zdjęcia cyfrowego?

 Kiedy oglądamy stare zdjęcie, na odwrocie często możemy znaleźć stempelek fotografa, notatkę na temat miejsca i daty zdjęcia, a nawet kto na nim jest. Ale gdzie jest “odwrotna strona” zdjęcia cyfrowego?
Kiedy oglądamy stare zdjęcie, na odwrocie często możemy znaleźć stempelek fotografa, notatkę na temat miejsca i daty zdjęcia, a nawet kto na nim jest. Ale gdzie jest “odwrotna strona” zdjęcia cyfrowego?
Nazwa pliku nie jest dobrym miejscem na zapisanie tych informacji. Okazuje się jednak, że obrazy cyfrowe mają “odwrotną stronę”, informacje o zdjęciu lub skanie, zapisaną wewnątrz pliku. Zapis ten nie zmienia samego obrazu, a do jego odczytania (i zapisania) potrzebujemy odpowiedniego narzędzia – programu.
Informacje są różnego typu. Kamera cyfrowa zapisuje wiele danych technicznych takich jak czas naświetlania, przesłona, liczba pixli i dane samej kamery. Te metadane zapisywane są w standardzie zwanym Exif. Przy przesyłaniu zdjęć przydatna jest informacja o tym, co jest na zdjęciu przedstawione, kto je zrobił, tytuł zdjęcia, autor, dane o prawach autorskich itp. Te dane zapisywane są w standardzie o nazwie IPTC. Zarówno Exif jak i IPTC zostały wprowadzone około 1995 roku, a więc są dość stare. Ma to swoje zalety – większość programów odczytujących zdjęcia potrafi odczytać te etykiety, a więc dane te są łatwo dostępne. Ale standardy te mają wiele wad:
- Nie wszystkie formaty plików cyfrowych mogą je zmieścić (np. obrazy w formacie png nie zawierają danych Exif).
- Liczba etykiet jest ograniczona bez możliwości dodania nowych – brakuje ważnych pól, np. osoby na zdjęciu.
- Zapis jest ograniczony w wielkości tekstu (mała liczba znaków), brak jest kodowania unicode (brak wsparcia dla polskich liter), brak możliwości zapisu w różnych językach i wiele innych.
Standardy metadanych: EAD

Ten blog jest trzecim w serii poświęconej standardom metadanych używanym w archiwach.
 EAD (Encoded Archival Description) jest standardem stworzonym specjalnie w celu zakodowania pomocy archiwalnych. Z tego powodu jest on pewnego rodzaju hybrydą. Z jednej strony stara się odzwierciedlić sposób, w jaki pracują archiwiści tworząc pomoce archiwalne, z drugiej stara się wprowadzić dyscyplinę i dokładność niezbędną do elektronicznej obróbki dokumentu. W wyniku mamy sporo dowolności w umiejscowieniu danych, co ułatwia pracę archiwiście a jednocześnie utrudnia wymianę danych. W nowej wersji EAD (EAD3), która jest w przygotowaniu od kilku lat, spodziewane jest zmniejszenie tych dowolności.
EAD (Encoded Archival Description) jest standardem stworzonym specjalnie w celu zakodowania pomocy archiwalnych. Z tego powodu jest on pewnego rodzaju hybrydą. Z jednej strony stara się odzwierciedlić sposób, w jaki pracują archiwiści tworząc pomoce archiwalne, z drugiej stara się wprowadzić dyscyplinę i dokładność niezbędną do elektronicznej obróbki dokumentu. W wyniku mamy sporo dowolności w umiejscowieniu danych, co ułatwia pracę archiwiście a jednocześnie utrudnia wymianę danych. W nowej wersji EAD (EAD3), która jest w przygotowaniu od kilku lat, spodziewane jest zmniejszenie tych dowolności.
Reguły i zasady tworzenia pomocy archiwalnych zawarte są w osobnych dokumentach. Oprócz zasad międzynarodowych – ISAD(G) – są również zasady tworzone w różnych krajach, jak np. DACS w USA, które są podobne ale posiadają często subtelne różnice. EAD jest formą zapisu tych danych w postaci zrozumiałej przez człowieka ale także nadającej się do obróbki komputerowej. Jak wszystkie nowoczesne standardy metadanych, wyrażony jest w XML i składa się z serii etykiet, takich jak <ead>, które mieszczą się w innych, wraz z regułami ich umieszczania i regułami dotyczącymi ich zawartości.
Osobiste archiwa cyfrowe
Archiwa osobiste nie sa niczym nowym. U mojej babci lezały na stoliku dwa piękne albumy, jeden z drewnianą okładką z płaskorzeźbą górala na tle Tatr. Albumy zawierały zdjęcia z młodości moich dziadków i pradziadków, z początków 20 wieku, w domu, w górach, na Powszechnej Wystawie Krajowej w Poznaniu (1929). Takie albumy były często zabierane jako jedyny dobytek, kiedy wojna zmuszała rodziny do opuszczenia domu i wędrówki w nieznane.
Dziś, kiedy nowe pokolenie żyje dniem dzisiejszym Internetu w Facebooku, Flickr-rze, Pintereście czy w Naszej Klasie, warto przypomnieć o tej tradycji. Archiwa instytucjonalne zajmuja się tylko ‘ważnymi’ sprawami lub osobami, ale w każym prawie domu są materiały które potencjalnie mogą kiedyś stać się ważne dla badacza historii. Albo nawet bezcenne.
Jak przenieśc tradycję robienia albumów, zbierania listów czy innych dokumentów w sferę elektroniczną? Zapisy sprzed 15 lat na dyskietkach są już często nie do odczytania, jeśli nawet potrafimy odcyfrować tekst w egzotycznym formacie z ubiegłego wieku. Trzeba się do tego zabrać inaczej, używając nowych narzędzi i tworząc nowa tradycję.
Otwarte czasopisma naukowe a prawa autorskie
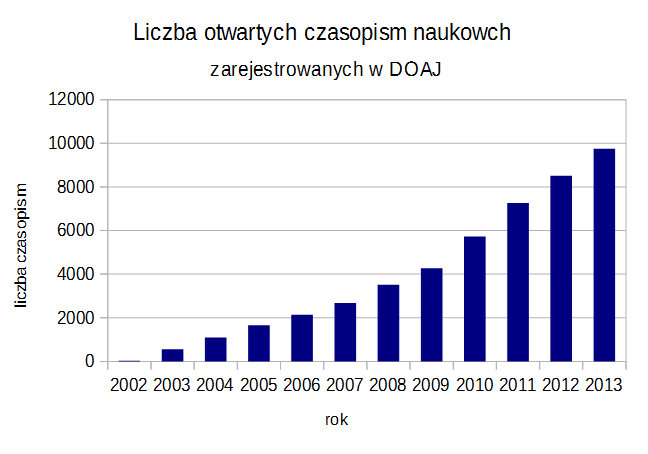
Prawo autorskie ma ogromne znaczenie dla rozpowszechniania dóbr kultury i nauki, w tym zasobów archiwalnych. Jednocześnie trudno znaleźć prawo, które byłoby bardziej zawiłe, niejasne, wewnętrznie sprzeczne i działające wstecz. Prawo autorskie w większości krajów coraz bardziej rozchodzi sie z rzeczywistością i powszechnym użyciem Internetu jako medium dostępu do dóbr kultury.
Problemy z prawem autorskim są wielorakie, to jest temat na większą rozprawę, tutaj tylko kilka przykładów dla ilustracji zakresu problemu. Biblioteki i archiwa mogą legalnie udostępniać każdemu zasoby – książki, dokumenty, czasopisma … ale tylko na miejscu. Zdalne oglądanie tego samego dokumentu jest zabronione przez prawo (chyba, że dokument ma ponad 120 lub więcej lat). Prawo autorskie nie zabrania dostępu, tylko ten dostęp utrudnia, stanowi równoważnik piasku sypanego w tryby maszyny przepływu informacji
Podobnie jest z domowym użyciem mediów. Każdy (w USA) może sobie legalnie zrobić kopie zapasową filmu (np. kupionego DVD), ale nie może legalnie wykonać kopii pliku zawierającego ten film na DVD (Digital Millennium Copyright Act).
Sytuacja jest szczególnie tragiczna w dziedzinie publikacji naukowych. Aby dostać kopię (elektroniczną) artykułu który sam napisałem, muszę zapłacić wydawcy średnio $30, sporo więcej niż za przeciętną książkę w księgarni. W dobie powszechniej dostępności wiadomości gazetowych w Internecie, bariery w dostępie do wiedzy naukowej są ogromne, i stan ten budzi rosnący sprzeciw. Jest to sprzeciw tym bardziej uzasadniony, że praca naukowców jest w dużej części finansowana przez państwo, uczelnie albo przez prywatne fundacje z założeniem, ze będą służyły całemu społeczeństwu. Coraz więcej naukowców domaga się publicznej dostępności swojej pracy. Wydawcy tradycyjnych publikacji naukowych próbują obronić się przed tym trendem i zachować stary model oferując publiczna dostępność artykułu za określoną opłatą z góry przy publikacji. Wydawcy argumentują, że potrzebują pieniędzy na opracowanie, skład, itp. Na przykład Elsevier, wydawca wielu czasopism naukowych, wycenia publikację otwartego artykułu na $3000.
Sąd apelacyjny wydaje decyzję w sprawie “dozwolonego użytku”

 10 czerwca 2014 r. Sąd Apelacyjny Drugiego Okręgu (południowy Nowy Jork) wydał wyrok, przychylając się do argumentów HathiTrust i odrzucając apel kilku organizacji autorskich, w tym m.in. amerykańskego Authors Guild i szwedzkiego Sveriges Författarförbund. W podsumowaniu wyroku czytamy:
10 czerwca 2014 r. Sąd Apelacyjny Drugiego Okręgu (południowy Nowy Jork) wydał wyrok, przychylając się do argumentów HathiTrust i odrzucając apel kilku organizacji autorskich, w tym m.in. amerykańskego Authors Guild i szwedzkiego Sveriges Författarförbund. W podsumowaniu wyroku czytamy:
“…utrzymujemy, że doktryna “dozwolonego użytku” pozwala pozwanym na stworzenie bazy danych umożliwiającej przeszukiwanie pełnotekstowe dzieł objętych prawami autorskimi i na dostarczenie tych dzieł w formatach dostępnych dla osób niepełnosprawnych.”
Czytaj dalej „Sąd apelacyjny wydaje decyzję w sprawie “dozwolonego użytku””
Wiki-konferencja USA 2014


Panel „Rola wikipedii w cztereach typach bibliotek”. Wiki-konferencja USA 2014. Foto Piotr Puchalski
W dniach 30 maja do 1 czerwca 2014 odbyła się w w New York Law School na Manhattanie konferencja “Wikiconference USA 2014”. Konferencja zgromadziła wikipedystów z USA, którzy przedstawiali i dyskutowali gorące obecnie tematy dotyczące Wikipedii a także jej siostrzanych organizacji skupionych w Wikimedia Foundation. Oprócz problemów technicznych, szkoleń i dnia poświęconego nieformalnemu spotkaniu (“Unconference”), wiele sesji poświęconych było tematom, które bliskie są instytucjom GLAM i organizacjom edukacyjnym, takim jak wykorzystanie Wikipedii w kursach akademickich, prawa autorskie, wikiprojekty i inne formy współpracy. Poniżej kilka refleksji z sesji w którch braliśmy udział, dzieląc się uczestnictwem w równoległych sesjach.
Dzień pierwszy konferencji zaowocował wieloma pomysłami na rozwój projektu GLAM Instytutu Piłsudskiego. Podczas sesji, na której cztery różne instytucje przedstawiały swój sposób na wykorzystanie Wikipedii, Natalie Milbrodt z Queens Library podzieliła się innowacyjnym pomysłem na „Edytaton”. „Edytaton” to zebranie osób zainteresowanych daną dziedziną, podczas którego, na podstawie dokumentów danej instytucji, osoby te piszą artykuły do Wikipedii, nauczywszy się najpierw podstaw edytowania. Czytaj dalej „Wiki-konferencja USA 2014”
Linked Data cz. 2: gdzie są dane?
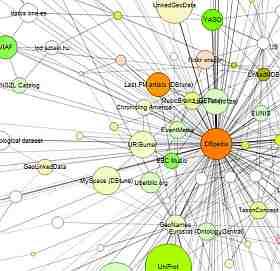

Fragment diagramu Linked Data z portalu LinkedData.org
Linked Data jest stosunkowo nowym zjawiskiem w sieci WWW, ideą dostępu do danych strukturalnych. Co to są dane strukturalne? WWW jest uniwersalnym nośnikiem informacji czytelnej dla człowieka – wszystkie strony internetowe, artykuły, aplikacje dają nam informacje, które możemy odczytać i zinterpretować, na przykład pytanie: „kiedy przyjedzie następny tramwaj?” i odpowiedź; “za 10 minut”. Takie pytanie i odpowiedź nie są jednak łatwe do odczytania przez komputery, które potrzebują informacji w ścisłej strukturze: (“Numer przystanku: 4398, linia tramwajowa: 11, odległość od przystanku: 0.8 km, itp.)
Informacja jest zwykle zapisana w bazach danych, które po wielu latach udoskonalania są bardzo wydajne w przechowywaniu i wyszukiwaniu danych, ale fatalne w wymianie informacji. Każda baza danych zawiera wiele kolumn, nazywanych raczej dowolnie i tylko lokalny system komputerowy umie z niej wyciągnąć dane. Nowy koncept, Linked Data, przybywa tutaj z pomocą. Schemat metadanych Linked Data, o nazwie RDF (Resource Description Framework, struktura opisu zasobów), wymaga, aby dane nie były prezentowane w trudnych do odcyfrowania tabelach, ale w prostych zdaniach, składający się z podmiotu, orzeczenia i dopełnienia. Zamiast wymyślonych nazw kolumn używamy nazw standardowych, a zamiast nazwy podmiotu używamy jego identyfikator URI (Universal Resource Identifier, uniwersalny identyfikator zasobu). Przykładowo, trywialna dla człowieka informacja o tytule tego blogu (przecież możemy przeczytać go powyżej, prawda?) zamienia się w zdanie albo “trójkę” w slangu RDF [1) www.archiwa.net/index.php?option=com_content&view=article&id=593&catid=95:blog&Itemid=42, 2) dc:title, 3) „Linked Data cz. 2: gdzie są dane?”]. Pierwsza część to adres URI jednoznacznie wskazujący na ten artykuł, druga to „tytuł” w konkretnym standardzie metadanych (Dublin Core), a trzecia część to tekst tytułu.
Hakerzy i archiwiści z NASA przywracają do świetności zagubione zdjęcia księżyca.


Wschód ziemi. W dolnej części odzyskane zdjęcie wysokiej jakości.
NASA opublikowało niedawno nowo odzyskane zdjęcia z sond księżycowych, wysyłanych w latach 1966-67 w ramach programu „Lunar Orbiter”. Różnica jakości pomiędzy starymi, opublikowanymi zdjęciami i nowym materiałem jest uderzająca. Historia uratowania materiału i odtworzenia wysokiej jakości obrazów jest pouczająca, a zaczyna się od roku 1986, kiedy to archiwistka Jet Propulsion Laboratory (JPL) Nancy Evans zdecydowała, że nie może, w dobrej wierze, zwyczajnie wyrzucić starego materiału.
Sondy wyposażone były kamery wysokiej jakości, z podwójnymi obiektywami, i wykonywały duże ilości zdjęć na taśmie 70 mm. Taśmy były potem wywoływane na pokładzie sondy, zdjęcia były skanowane i wysyłane na ziemię. Modulowany sygnał z sondy, był zapisywany na taśmę magnetyczną, wraz z komentarzami operatorów. Następnie cała sonda (z oryginałami zdjęć) była bezceremonialnie rozbijana o powierzchnię księżyca. Taśmy magnetyczne były wykorzystane do wydrukowania dużych obrazów na papierze (wynajmowano stare kościoły aby rozwiesić ogromne arkusze), które używano do zidentyfikowania potencjalnych miejsc lądowania na księżycu. Następnie taśmy były załadowane do pudeł i zapomniane.
Czytaj dalej „Hakerzy i archiwiści z NASA przywracają do świetności zagubione zdjęcia księżyca.”