

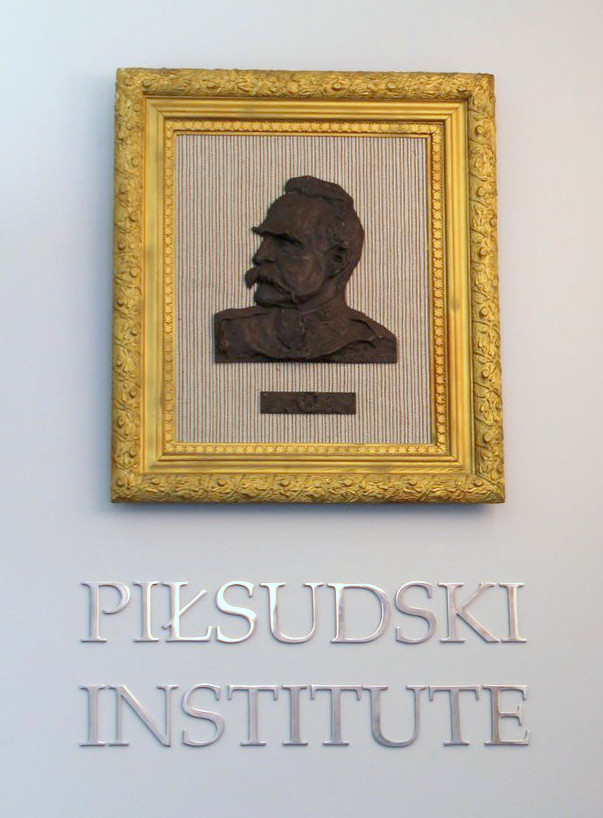 Kto lubi przeprowadzki?
Kto lubi przeprowadzki?
I wszystko, co się z tym wiąże: segregowanie, redukowanie, pakowanie, przewożenie, rozpakowywanie, ustawianie….? O ile można w miarę sprawnie przenieść się z mieszkania do mieszkania, to przeprowadzenie zmiany lokalu instytucji, która od ćwierćwiecza zajmowała kamienicę w centrum Manhattanu, gromadząc archiwa, dzieła sztuki i eksponaty muzealne, trudno sobie wyobrazić.
Wieść o sprzedaży domu, który wynajmował Instytut Piłsudskiego w Ameryce na swoją siedzibę, była dużym zaskoczeniem dla jego pracowników. Instytut kojarzony był od wielu lat z Drugą Aleją na Manhattanie, miał stałe grono przyjaciół, wielbicieli, odwiedzających oraz badaczy, a tu nagle taka wiadomość! Niełatwo było się z nią pogodzić, ale innego wyjścia nie było. Niezwłocznie zorganizowano Kampanię Na Rzecz Przyszłości w celu zebrania funduszy na to przedsięwzięcie i opracowano logistykę zmiany lokalizacji. Przygotowania trwały ponad rok. Przede wszystkim musieliśmy znaleźć nową siedzibę, która pomieściłby nasze zbiory i zapewniła sprawne kontynuowanie działalności Instytutu.  Najbardziej przypadł nam do gustu lokal zaproponowany przez Polsko-Słowiańską Federalną Unię Kredytową, a także warunki jego wynajmu.
Najbardziej przypadł nam do gustu lokal zaproponowany przez Polsko-Słowiańską Federalną Unię Kredytową, a także warunki jego wynajmu.  Rozpoczęły się prace adaptacyjne: zaprojektowanie i zabudowanie wnętrza, instalacja profesjonalnych zabezpieczeń, regałów oraz montowanie przestronnych szaf. Nieocenioną pomoc otrzymaliśmy z Instytutu Pamięci Narodowej, z którego oddelegowano ośmiu archiwistów, którzy w ciągu dwóch miesięcy profesjonalnie i sprawnie zapakowali archiwa oraz zbiory biblioteczne i pomagali w przenoszeniu ich do nowego lokum. Nie byliśmy w stanie policzyć tych wszystkich pudeł i paczek, które po przewiezieniu na nowe miejsce, zajęły większość powierzchni użytkowej, piętrząc się niemal pod sufit.
Rozpoczęły się prace adaptacyjne: zaprojektowanie i zabudowanie wnętrza, instalacja profesjonalnych zabezpieczeń, regałów oraz montowanie przestronnych szaf. Nieocenioną pomoc otrzymaliśmy z Instytutu Pamięci Narodowej, z którego oddelegowano ośmiu archiwistów, którzy w ciągu dwóch miesięcy profesjonalnie i sprawnie zapakowali archiwa oraz zbiory biblioteczne i pomagali w przenoszeniu ich do nowego lokum. Nie byliśmy w stanie policzyć tych wszystkich pudeł i paczek, które po przewiezieniu na nowe miejsce, zajęły większość powierzchni użytkowej, piętrząc się niemal pod sufit.
Czytaj dalej „Instytut Piłsudskego w Ameryce zmienił siedzibę.”

 Jednym z najważniejszych zadań systemu zarządzania aktami (RM) jest dokumentowanie działalności instytucji czy organizacji, tworzenie zapisanej i niezmienialnej pamięci jej działalności i historii, zapisywanie dowodów które mogą być użyte (np. przez historyka lub sąd) z pewnością, że nie zostały one zmienione czy zafałszowane. W tym aspekcie MoReq2012 jest istotny również dla archiwów, których funkcja pokrywa się w dużym stopniu z tymi zadaniami.
Jednym z najważniejszych zadań systemu zarządzania aktami (RM) jest dokumentowanie działalności instytucji czy organizacji, tworzenie zapisanej i niezmienialnej pamięci jej działalności i historii, zapisywanie dowodów które mogą być użyte (np. przez historyka lub sąd) z pewnością, że nie zostały one zmienione czy zafałszowane. W tym aspekcie MoReq2012 jest istotny również dla archiwów, których funkcja pokrywa się w dużym stopniu z tymi zadaniami.




 Na niedawnej konferencji METRO (Metropolitan New York Library Council) miała miejsce prezentacja przedstawicieli grupy ‘Humanistyka Cyfrowa w New York City’ (NYCDH). Grupa ta działa od połowy 2011, i zrzesza zainteresowanych Humanistyką Cyfrową z Nowego Jorku i okolic. Dostarcza ona forum wielu różnym organizacjom i małym grupom osób które pracują nad jakimiś problemami związanymi z humanistyką cyfrową. Uczelnie, w których pracują członkowie komisji sterującej grupy (takie jak NYU, CUNY, Columbia, Pratt i inne) udzielają miejsca na spotkania. Kalendarz grupy jest pełny, często jest kilka wydarzeń lub spotkań w tygodniu. Grupa jest otwarta, i po zarejestrowaniu się każdy członek może wpisać w kalendarz imprezę jaka organizuje i wziąć udział w już ogłoszonej.
Na niedawnej konferencji METRO (Metropolitan New York Library Council) miała miejsce prezentacja przedstawicieli grupy ‘Humanistyka Cyfrowa w New York City’ (NYCDH). Grupa ta działa od połowy 2011, i zrzesza zainteresowanych Humanistyką Cyfrową z Nowego Jorku i okolic. Dostarcza ona forum wielu różnym organizacjom i małym grupom osób które pracują nad jakimiś problemami związanymi z humanistyką cyfrową. Uczelnie, w których pracują członkowie komisji sterującej grupy (takie jak NYU, CUNY, Columbia, Pratt i inne) udzielają miejsca na spotkania. Kalendarz grupy jest pełny, często jest kilka wydarzeń lub spotkań w tygodniu. Grupa jest otwarta, i po zarejestrowaniu się każdy członek może wpisać w kalendarz imprezę jaka organizuje i wziąć udział w już ogłoszonej.



{kind=link}