
15 listopada 2023 r. odbył się International studyday on early implementations of records in contexts / Journée d’étude internationale sur les premières implémentations de records in contexts – spotkanie poświęcone prezentacji nowego standardu Międzynarodowej Rady Archiwów oraz doświadczeniom ze stosowania jego wcześniejszych wersji roboczych. Odbywało się ono stacjonarnie w Archiwum Narodowym Francji w Pierrefitte-sur-Seine z jednoczesną transmisją on-line. W spotkaniu wzięło udział kilkaset osób z wielu krajów i kontynentów, w tym ponad 300 on-line. Wśród nich było kilkoro pracowników sieci Archiwów Państwowych, w tym troje z Naczelnej Dyrekcji Archiwów Państwowych.
Zgromadzonych powitała, w imieniu Bruno Ricarda, dyrektora Archiwum Narodowego, Marie-Françoise Limon-Bonnet, kierująca oddziałem akt notarialnych w tymże archiwum, oraz Josée Kirps, przewodnicząca Międzynarodowej Rady Archiwów. Program obrad był bardzo bogaty – obejmował 22 wystąpienia zgrupowane w pięciu sesjach.
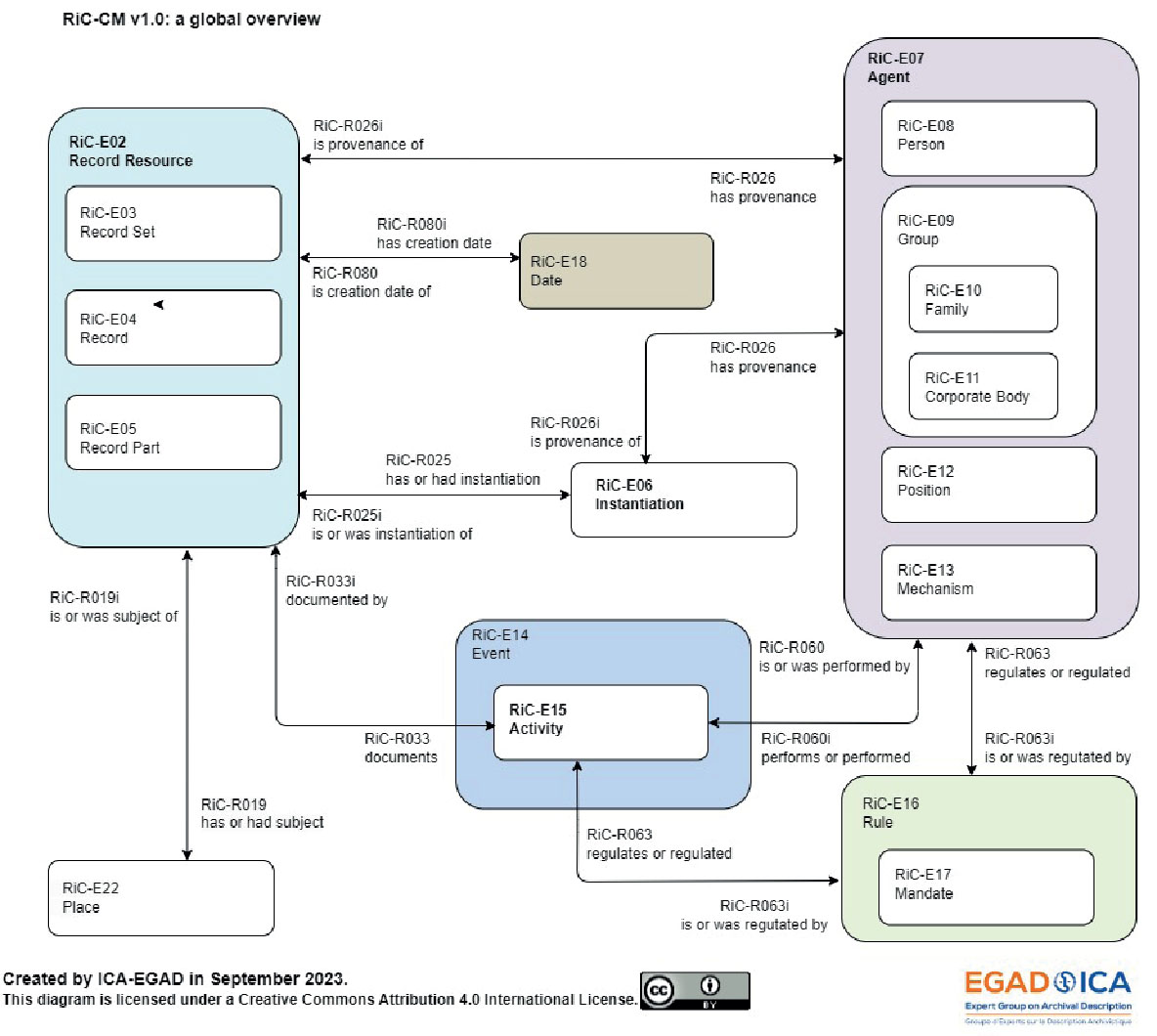
W sesji wprowadzającej przedstawiono nowy standard Records in Contexts w różnych kontekstach – jego aktualny kształt i związki z innymi standardami. Daniel Pitti (przewodniczący ICA/EGAD) powiedział, że docelowo standard będzie miał 4 części, z których trzymają już obecnie wersję 1.0 (RiC-FAD, RiC-CM i RiC-O). RiC-FAD wyodrębniony ze wcześniejszych wersji wstępu do RiC-CM. W przygotowaniu jest jeszcze RiC-AG czyli wskazówki wdrożeniowe. D. Pitti przybliżył następnie RiC-CM – Conceptual Model, jego związki i różnice w porównaniu do pierwszego standardu ISAD (G). Widać w nimefektydoświadczeń archiwistów i prac badawczych oraz wpływ rozwoju narzędzi technologicznych, bowiem w miejsce wielopoziomowego hierarchicznego opisu zaproponowano opis wielowymiarowy w formie grafu lub sieci zlinkowanych jednostek opisu. Jego bazowa struktura obejmuje 19 jednostek opisu, 42 elementy opisu, czasem wspólne dla kilku jednostek opisu, oraz 85 relacji – 15 symetrycznych i 70 jednostronnych.

Źródło: Journée d’étude internationale de l’EGAD
sur les premières implémentations de Records in Contexts
Następnie Florence Clavaud (członek grupy ICA/EGAD) przedstawiłazmiany, jakie wprowadzono w RiC-Ontology 0.2, aby osiągnąć wersję 1.0-beta. Zapewniła, że najnowsza wersja jest w pełni zgodna z RiC-CM. Zachęcała też do dalszej współpracy przy rozwoju tego modelu, np. za pośrednictwem grupy dyskusyjnej https://groups.google.com/g/Records_in_Contexts_users.
O standardach technicznych, dzięki którym standardy opisu MRA mogą być stosowane przez twórców systemów informacji archiwalnej, opowiedziała Kerstin Arnold (odpowiedzialna za Europejski Portal Archiwalny). Z jej wypowiedzi wynika, że obecnie nadal funkcjonują i są rozwijane: EAD – dla ISAD(G), EAC – dla ISAAR(CPF),EAG – dla ISDIAH oraz tworzony jest EAC-F – dla ISDF. Przygotowany został także Encoded Archival System – EAS zgodny z RiC-CM. RiC-O ma jednak inną koncepcję i może być raczej przedstawiany nie w XML, a w RDF. W dyskusji K. Arnold dodała, że administratorzy Europejskiego Portalu Archiwalnego przymierzają się do implementacji RiC-CM.
Normalizację metadanych, dodawanych do dokumentów na różnych etapach ich cyklu życia, przedstawił Adrian Cunningham(członek grupy ICA/EGAD) na podstawie relacji między normą ISO 23081 Informacja i dokumentacja aRiC. Obie z nich są kompleksowe, jedna nie może być włączona do drugiej, ani jej zastąpić, potrzebna jest więc ich współpraca. Prelegent wskazywał więcelementy opisuwskazane w obu normach,istotne do zapisania i zachowania na etapie tworzenia i archiwizacji dokumentów: kto, dlaczego, kiedy, jak i gdzie; dane techniczne, dane zarządzania i zachowania. Upraszczając – podstawowy model metadanych powinien obejmować agenta (twórca), działania (funkcje) i dokumenty (archiwalia).
PREMIS jako model danych i ich zapisu w XML i RDF w celu zachowania w postaci elektronicznej przedstawił Bertrand Caron (Biblioteka Narodowa Francji). Wskazywał związki PREMIS z innymi standardami oraz wielkie znaczenie stosowania w systemach informacyjnych słowników kontrolowanych.
Kolejna sesja obejmowała omówienia 9 różnorodnych dotychczasowych projektów badawczych oraz przykładów zastosowania przez różne instytucje projektowanych modeli Records in Contexts. O doświadczeniach mówili przedstawiciele archiwów narodowych Francji, Norwegii, Szwecji i w Singapurze. We wszystkich wypowiedziach wspominano wcześniejsze banki danych, zgromadzone w różnych formatach, standardach i zbiorach, oraz konieczność wypracowania sposobu ich unifikacji w celu uzyskania jednolitego formatu docelowego. Wdrażanie RiC w pracy systemów informacyjnych podjęto także w instytucjach innych niż archiwa narodowe. Tematykę i przebieg tych prac przedstawili przedstawiciele Archiwum Miejskiego w Amsterdamie w Holandii, Archiwum Kantonalnego Vaud w Szwajcarii, Fundacji Archiwów Notarialnych i Uniwersytetu w Malcie oraz Rijksmuseum Amsterdam w Holandii.
W trzeciej sesji zaprezentowano narzędzia i systemy służące do gromadzenia danych zgodnych z RiC. Przedstawiciele Archiwum Narodowego Francji uwagę swoją skupili na przygotowanym konwerterze danych z dotychczasowych formatów EAD i EAC do RiC. Pozostałe zaprezentowane projekty o charakterze raczej badawczym, w ramach których przygotowano systemy informatyczne, prowadzono w Centrum Badań Rosyjskich, Kaukaskich i Środkowoeuropejskich w Paryżu (projekt Off-Site) oraz w kilku instytucjach lokalnych i organizacjach społecznych w Szwajcarii (Docuteam AG).
Od strony merytorycznej spojrzeli na RiC uczestnicy kolejnych projektów badawczych, w których zastosowano standard do opisu efektów badań. W czwartej sesji można było wysłuchać wystąpień na temat czterech takich projektów. ORESM, prowadzony przez kilka instytucji naukowych w Paryżu, dotyczy dokumentów o studentach i pracownikach naukowych średniowiecznego uniwersytetu w Paryżu. Josip Spec (archiwum Narodowego Banku Szwajcarii)bardzo sugestywnie, krok po kroku, przedstawił zagadnienie migracji danych instytucji kulturalnych w szwajcarskim kantonie Zougz formatu ISAD(G) do RiC. Wymienił kolejne działania i wynikające z nich konstruktywne wnioski. Końcowe konkluzje z przeprowadzonego procesu, które mogą stanowić zalecenia na przyszłość, to: prawo własności posiadanych danych, poprawne modelowanie danych, korygowanie danych, stosowanie przyjaznego GUI, różne wewnętrzne i zewnętrzne zastosowanie RiC oraz zaangażowanie osób z wiedzą i zdolnościami. Kolejny konkretny projekt przedstawiła Joy Walser. Dotyczył on gromadzenia opisów obiektów sfragistycznych Archiwum Narodowego Liechtensteinu. Wyzwania stanowiły: różne pochodzenie obiektów, przynależność do różnych części zasobu (zespoły instytucji, spuścizny osób prywatnych, zbiory) oraz mało danych na temat konkretnych obiektów. W trakcie prac konieczne było opracowanie i rozwinięcie trzyczęściowego modelu opisu (zbiór dokumentów, dokument i osoba). Ważne było także dołączenie do systemu informacji zewnętrznych źródeł i zbiorów danych, np. słownika historycznego czy Wikidata. Te dwa wystąpienia otrzymały pozytywne opinie na chacie spotkania. Ostatnie wystąpienie w tej sesji dotyczyło projektu InterPARES Trust AI. Hugolin Bergier z Uniwersytetu w Denver w USA próbował w nim odpowiedzieć na pytanie, na ile sztuczna inteligencja może być przydatna w RiC-O. Pytanie nadal jest otwarte, jako że projekt przewidziany jest na lata 2021-2026.
Ostatnie trzy wystąpienia, w piątej sesji, dotyczyły zastosowania RiC na portalach prowadzonych we współpracy kilku instytucji. Były to: Portal szwajcarskiego audiowizualnego dziedzictwa Memobase de Memoriav, FranceArchives – narodowy portal archiwalny we Francji oraz zarządzany przez Bibliotekę Państwową w Berlinie projekt SoNAR, tworzący system informacji o związkach różnych osób i gromadzący dane zarówno z publikacji i opisów bibliograficznych, jak i z archiwaliów.
Na zakończenie każdej sesji był czas na zadawanie pytań – na żywo i na czacie, a prelegenci lub prowadzący udzielali odpowiedzi. Istotne pytania zostały zadane („poza konkursem”) na czacie przez niezależnego archiwistę ze Szwajcarii: czy norma RiC jest oficjalnie rekomendowana przez MRA, czy dawne normy nadal są rekomendowane przez MRA, czyli jednocześnie ISAD(G) i RiC oraz czy można przewidzieć potencjalne konflikty między poprzednimi standardami a RiC.
Organizatorzy seminarium zapowiedzieli udostępnienie nagrania wystąpień oraz wskazali portal https://github.com/ICA-EGAD, na którym są i będą udostępniane kolejne wersje standardu RiC.
Źródło: Journée d’étude internationale de l’EGAD sur les premières implémentations de Records in Contexts
Anna Laszuk i Adam Baniecki
(NDAP) AP Wrocław O. Bolesławiec
O standardach technicznych, dzięki którym standardy opisu MRA mogą być stosowane przez twórców systemów informacji archiwalnej, opowiedziała Kerstin Arnold (odpowiedzialna za Europejski Portal Archiwalny). Z jej wypowiedzi wynika, że obecnie nadal funkcjonują i są rozwijane: EAD – dla ISAD(G), EAC – dla ISAAR(CPF),EAG – dla ISDIAH oraz tworzony jest EAC-F – dla ISDF. Przygotowany został także Encoded Archival System – EAS zgodny z RiC-CM. RiC-O ma jednak inną koncepcję i może być raczej przedstawiany nie w XML, a w RDF. W dyskusji K. Arnold dodała, że administratorzy Europejskiego Portalu Archiwalnego przymierzają się do implementacji RiC-CM.
Normalizację metadanych, dodawanych do dokumentów na różnych etapach ich cyklu życia, przedstawił Adrian Cunningham(członek grupy ICA/EGAD) na podstawie relacji między normą ISO 23081 Informacja i dokumentacja aRiC. Obie z nich są kompleksowe, jedna nie może być włączona do drugiej, ani jej zastąpić, potrzebna jest więc ich współpraca. Prelegent wskazywał więcelementy opisuwskazane w obu normach,istotne do zapisania i zachowania na etapie tworzenia i archiwizacji dokumentów: kto, dlaczego, kiedy, jak i gdzie; dane techniczne, dane zarządzania i zachowania. Upraszczając – podstawowy model metadanych powinien obejmować agenta (twórca), działania (funkcje) i dokumenty (archiwalia).